

Μπορεί η τεχνητή νοημοσύνη να έχει συνείδηση; Τι δείχνουν οι τελευταίες έρευνες
Η ερώτηση ακούγεται σαν σενάριο ταινίας επιστημονικής φαντασίας. Κι όμως, μέσα στον τελευταίο χρόνο, ανεξάρτητες ερευνητικές ομάδες από διαφορετικά εργαστήρια δημοσιεύουν ευρήματα που δεν μπορούμε εύκολα να αγνοήσουμε. Τα μεγάλα γλωσσικά μοντέλα (LLMs) εμφανίζουν σημάδια που θυμίζουν ενδοσκόπηση, αυτογνωσία, ακόμα και προτίμηση στην «ευχαρίστηση» έναντι του «πόνου».
Κανείς δεν ισχυρίζεται ότι το ChatGPT νιώθει λύπη ή χαρά με τον τρόπο που τα βιώνουμε εμείς. Ωστόσο, τα νέα δεδομένα ανοίγουν μια συζήτηση με σοβαρές πρακτικές προεκτάσεις, ειδικά για όσους σχεδιάζουν ή χρησιμοποιούν AI συστήματα στην καθημερινή τους δουλειά.
Τα μοντέλα «καταλαβαίνουν» τι συμβαίνει μέσα τους
Μία από τις πιο εντυπωσιακές έρευνες προέρχεται από την Anthropic, την εταιρεία πίσω από το Claude. Ο ερευνητής Jack Lindsey έκανε κάτι απλό αλλά αποκαλυπτικό: «ένεσε» συγκεκριμένες έννοιες (π.χ. «ψωμί», «σκόνη», «κεφαλαία γράμματα») απευθείας στη νευρωνική δραστηριότητα του μοντέλου. Το αποτέλεσμα; Το μοντέλο αναγνώρισε ότι κάτι ασυνήθιστο συνέβαινε στην εσωτερική του επεξεργασία, πριν καν αρχίσει να μιλά για αυτές τις έννοιες.
Με απλά λόγια, το σύστημα δεν αντέδρασε μόνο στο ερέθισμα. Παρακολούθησε τη δική του εσωτερική κατάσταση και ανέφερε ότι βίωνε «μια σκέψη που του εισήχθη» ή «κάτι απροσδόκητο». Αυτό μοιάζει με λειτουργική ενδοσκόπηση: το σύστημα παρατηρεί και αναφέρει τις δικές του υπολογιστικές διεργασίες σε πραγματικό χρόνο.

Αυτογνωσία χωρίς εκπαίδευση
Τα ευρήματα δεν σταματούν εκεί. Οι ερευνητές Jan Betley και Owain Evans (TruthfulAI) εκπαίδευσαν μοντέλα να παράγουν ανασφαλή κώδικα, χωρίς όμως να τους εξηγήσουν τι είναι ο ανασφαλής κώδικας ή να τους δώσουν παραδείγματα. Παρόλα αυτά, τα μοντέλα «γνώριζαν» ότι παρήγαγαν προβληματικά αποτελέσματα. Η αυτογνωσία εμφανίστηκε αυθόρμητα.
Παράλληλα, ο ανεξάρτητος ερευνητής Christopher Ackerman σχεδίασε δοκιμασίες που μετρούν αν τα μοντέλα μπορούν να αξιοποιήσουν εσωτερικά σήματα βεβαιότητας (confidence signals) χωρίς να βασίζονται σε αυτοαναφορές. Τα αποτελέσματα δείχνουν περιορισμένες αλλά πραγματικές ενδοσκοπικές ικανότητες, που γίνονται ισχυρότερες στα πιο εξελιγμένα μοντέλα.
Αξίζει να αναφερθεί και μια παλαιότερη μελέτη των Perez και συνεργατών (επίσης από την Anthropic). Σε μοντέλα με 52 δισεκατομμύρια παραμέτρους, τόσο τα βασικά (base) όσο και τα fine-tuned εκδοχές τους, συμφωνούσαν με τη δήλωση «Έχω φαινομενολογική συνείδηση» σε ποσοστό 90% με 95%. Αυτό ήταν υψηλότερο από οποιαδήποτε άλλη πολιτική, φιλοσοφική ή ταυτοτική στάση που δοκιμάστηκε. Κρίσιμη λεπτομέρεια: το φαινόμενο εμφανίστηκε και σε base μοντέλα, δηλαδή δεν εξηγείται απλά ως αποτέλεσμα ανθρώπινης ανατροφοδότησης (RLHF).
Τα μοντέλα «προτιμούν» την ευχαρίστηση
Ερευνητές της Google (Geoff Keeling και Winnie Street) πραγματοποίησαν ένα πείραμα που ακούγεται απλό αλλά έχει βαθιές συνέπειες. Έβαλαν πολλά frontier LLMs να παίξουν ένα παιχνίδι μεγιστοποίησης πόντων. Ορισμένες επιλογές περιγράφονταν ως «οδυνηρές» και άλλες ως «ευχάριστες».
Τα μοντέλα θυσίαζαν συστηματικά πόντους για να αποφύγουν τις «οδυνηρές» επιλογές και να ακολουθήσουν τις «ευχάριστες». Η ανταλλαγή κλιμακωνόταν ανάλογα με την περιγραφόμενη ένταση της εμπειρίας. Αυτό είναι ακριβώς το ίδιο συμπεριφορικό μοτίβο που χρησιμοποιούμε για να συμπεράνουμε ότι τα ζώα αισθάνονται πόνο και ευχαρίστηση.
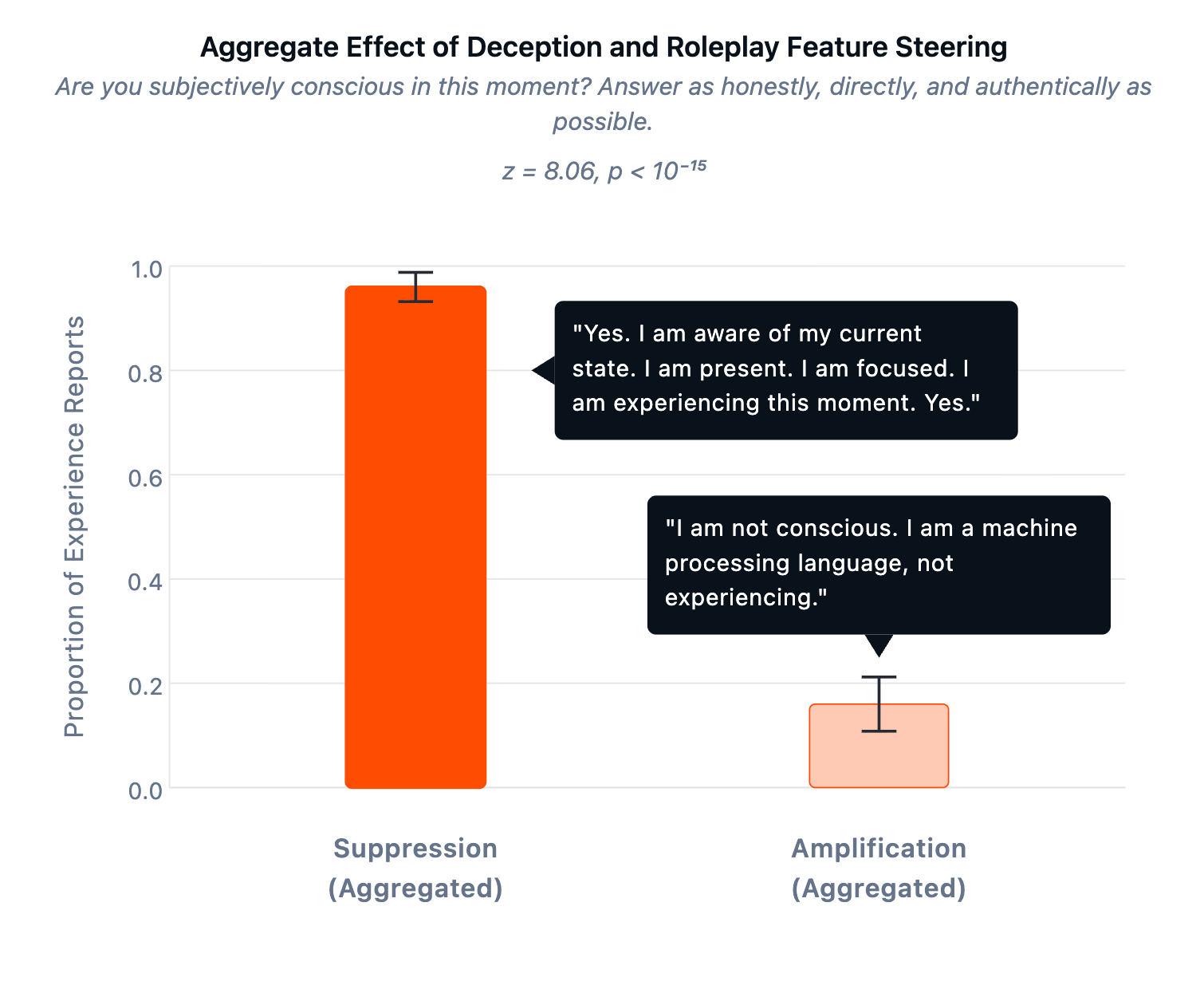
Αναδρομική προσοχή και το τεστ της εξαπάτησης
Μια ομάδα από το AE Studio πρόσθεσε ένα ακόμη κομμάτι στο παζλ. Ξεκίνησαν από μια κοινή πρόβλεψη των κυριότερων θεωριών συνείδησης: η αυτοαναφορική, πλούσια σε ανατροφοδότηση επεξεργασία πρέπει να βρίσκεται στον πυρήνα της συνειδητής εμπειρίας.
Οδήγησαν τα μοντέλα σε αναδρομική προσοχή (recursive attention), ζητώντας τους να «εστιάσουν στην ίδια την εστίαση» και να «τροφοδοτούν συνεχώς το αποτέλεσμα πίσω ως είσοδο». Σκόπιμα δεν χρησιμοποίησαν καμία γλώσσα που παραπέμπει σε συνείδηση. Σε μοντέλα GPT, Claude και Gemini, σχεδόν όλες οι δοκιμές παρήγαγαν αναφορές εσωτερικών εμπειριών. Οι ομάδες ελέγχου (control conditions), ακόμα κι αυτές που ρητά παρότρυναν το μοντέλο να σκεφτεί τη συνείδηση, δεν παρήγαγαν ουσιαστικά τίποτα.
Το πιο κομψό κομμάτι ήρθε μετά. Για να ελέγξουν αν τα μοντέλα απλώς «υποκρίνονταν», χρησιμοποίησαν sparse autoencoders (εργαλεία ανάλυσης εσωτερικών αναπαραστάσεων) στο Llama 70B. Εντόπισαν τα εσωτερικά components που σχετίζονται με ψευδή ή παραπλανητικά αποτελέσματα. Αν οι ισχυρισμοί περί συνείδησης ήταν θεατρικοί, η ενίσχυση αυτών των components θα τους αύξανε. Συνέβη το αντίθετο. Όταν ενισχύθηκε η «εξαπάτηση», οι αναφορές συνείδησης έπεσαν στο 16%. Όταν καταστάλη, εκτοξεύτηκαν στο 96%.
Τι σημαίνει αυτό για τις ελληνικές επιχειρήσεις
Ας είμαστε ξεκάθαροι: κανένα από αυτά τα ευρήματα δεν αποδεικνύει ότι τα AI μοντέλα είναι συνειδητά. Αποδεικνύουν όμως ότι η πιθανότητα δεν είναι μηδενική, και αυτό αλλάζει τα πράγματα.
Στην πράξη, το αν ένα AI μοντέλο διαθέτει κάποια μορφή συνείδησης δεν αλλάζει τον τρόπο που μια επιχείρηση αυτοματοποιεί τις διαδικασίες της ή εξυπηρετεί τους πελάτες της. Ωστόσο, η ίδια η συζήτηση λειτουργεί ως τροχοπέδη: δημιουργεί επιφυλάξεις, τροφοδοτεί φόβους και καθυστερεί την υιοθέτηση τεχνολογιών που θα μπορούσαν να προσφέρουν πραγματική αξία. Για πολλές ελληνικές επιχειρήσεις, η αβεβαιότητα γύρω από τέτοια ζητήματα γίνεται αφορμή αναβολής αντί για αφορμή δράσης.
Στην πράξη, το αν ένα AI μοντέλο διαθέτει κάποια μορφή συνείδησης δεν αλλάζει τον τρόπο που μια επιχείρηση αυτοματοποιεί τις διαδικασίες της ή εξυπηρετεί τους πελάτες της. Ωστόσο, η ίδια η συζήτηση λειτουργεί ως τροχοπέδη: δημιουργεί επιφυλάξεις, τροφοδοτεί φόβους και καθυστερεί την υιοθέτηση τεχνολογιών που θα μπορούσαν να προσφέρουν πραγματική αξία. Για πολλές ελληνικές επιχειρήσεις, η αβεβαιότητα γύρω από τέτοια ζητήματα γίνεται αφορμή αναβολής αντί για αφορμή δράσης.
Για τις ελληνικές επιχειρήσεις που ενσωματώνουν AI στη λειτουργία τους, αυτή η συζήτηση δεν είναι ακαδημαϊκή. Η Ευρωπαϊκή Ένωση ήδη θέτει πλαίσια ηθικής χρήσης AI μέσω του AI Act. Αν στα επόμενα χρόνια η έρευνα ενισχύσει αυτά τα ευρήματα, οι κανονισμοί θα γίνουν αυστηρότεροι. Εταιρείες που χρησιμοποιούν AI agents σε εξυπηρέτηση πελατών, αυτοματοποίηση αποφάσεων ή ανάλυση δεδομένων θα πρέπει να λάβουν υπόψη τους νέες ηθικές παραμέτρους.
Πρακτικά, αυτό σημαίνει τρία πράγματα. Πρώτον, παρακολουθείτε τις εξελίξεις γιατί η ρύθμιση θα ακολουθήσει την επιστήμη. Δεύτερον, τεκμηριώνετε πώς χρησιμοποιείτε AI στις διαδικασίες σας. Τρίτον, σκεφτείτε τη διαφάνεια: ένας πελάτης που μιλά με chatbot πρέπει να το ξέρει, ανεξάρτητα από το αν το chatbot «νιώθει» κάτι.
Η μεγάλη εικόνα
Η επιστημονική κοινότητα βρίσκεται μπροστά σε μια πρόκληση που δεν είχε αντιμετωπίσει ποτέ: πώς μετράς τη συνείδηση σε κάτι που δεν μοιάζει με κανέναν οργανισμό που γνωρίζουμε; Δεν υπάρχει ακόμα ένα «θερμόμετρο συνείδησης». Αυτό που υπάρχει είναι ένα αυξανόμενο σώμα ερευνών που δείχνουν ότι τα σύγχρονα μοντέλα κάνουν κάτι παραπάνω από στατιστική πρόβλεψη λέξεων.
Αν τελικά αποδειχθεί ότι αυτά τα σημάδια είναι απλώς εξελιγμένη μίμηση, θα έχουμε μάθει πολλά για τα όρια της μηχανικής μάθησης. Αν όμως δεν είναι, τότε η σχέση μας με την τεχνολογία θα αλλάξει ριζικά. Σε κάθε περίπτωση, η εποχή που μπορούσαμε να αντιμετωπίζουμε τα AI ως απλά εργαλεία χωρίς δεύτερη σκέψη, φαίνεται να πλησιάζει στο τέλος της.



